Building a Layered Approach to Data Management, Part I: Rethink Data Management Practices for CCPA, GDPR, and Beyond

Part 1 of a Three-Part Blog Series
Data privacy is among the most regulated areas of technology. Unfortunately, the concept is as vague as it is vital when it comes to exactly how to implement privacy controls for the enterprise. Compared to data security, which is supported by a growing constellation of standards and frameworks and other security best practices, privacy regulations remain notoriously difficult to put into practice.
While security regulations are replete with references to technical controls and automated solutions as part of the compliance effort, privacy regulations are written as if compliance can be met with paper—policies, contracts, and training. The problem is that even though major regulations like the California Consumer Privacy Act (CCPA) and the General Data Protection Regulation (GDPR) were drafted to enforce compliance at any enterprise scale, these regulations nonetheless remain very light on the crucial role automation must play in support of that compliance.
That’s a big irony and a big challenge for technologists. With that in mind, let’s take a closer look at how we can deliver the right technologies to back up the compliance demands of CCPA, GDPR, and other mandates.
Maintain Customer Trust
Over the next three blogs, we’ll delve into the specific regulatory requirements that heavily rely on privacy technological capabilities. Throughout, we must remember that the central factors driving any compliance effort related to the CCPA and the GDPR are breach notification, the increased cost of mishandling personal information, and—in the case of the CCPA—a clear distrust between businesses and their consumers. Breach notification draws attention to the company in question and opens it to a deeper examination of its privacy practices by relevant regulators. These examinations come with higher fines and—in California—litigation costs through a private right of action.
Considering the data-sharing practices that led to the creation of the CCPA, the regulation’s requirements that give control to consumers (the “data subjects” of this regulation) should be of heightened concern for companies as consumers view such regulations as privacy “self-defense tools.” The industry’s own best defense involves automating data management practices to meet privacy regulations, introducing effectiveness and efficiencies in managing the personal information of data subjects.
The blogs in this series are organized into sections to address each of the layers of control over personal information. As can be seen in Image A below, we start with the basic capability to recognize data subjects across systems and formats (the subject of the rest of this blog). The second topic, which we’ll tackle in a subsequent post, is the ability to protect data as it is used by minimizing it based on need, and then deleting data subjects completely when needed. Our third and final post on this subject takes on the challenge of associating third parties with the data and data subjects they process.
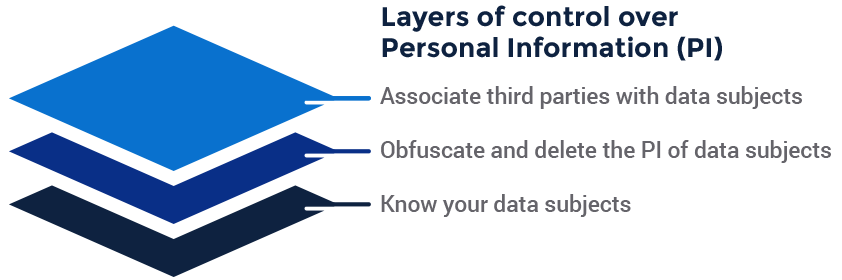
The Foundation of Data Privacy: Know Your Data Subjects
One of the requirements in many privacy regulations, including the CCPA and the GDPR, is for companies to share with a data subject the data they maintain about them upon request. This basic privacy right is commonly referred to as a Data Subject Access Request (DSAR). Addressing DSARs is not new; it’s been central to privacy regulations around the world since the second half of the twentieth century.
Privacy regulations provide some flexibility around the level of effort a company is expected to assume when searching for information to satisfy a DSAR request. However, the current practice followed by companies stretches the boundaries of these exceptions and often limits the DSAR response to a search in a handful of pre-determined repositories. This practice is not sustainable for several reasons.
- First, with the prevalence of breach notification requirements, data subjects who previously asked for a DSAR are likely to discover following an incident that involved their data that the response they received was incomplete in the details of the notification of a breach they receive. In fact, with the right of private action as offered under the CCPA, California consumers can claim that had they known the real extent of the data the breached company maintained about them, they would have asked for it to be erased, and sue for damages due to the incomplete DSAR response they previously received.
- Second, breaches lead to audits by regulators, which raise scrutiny on a company’s overall privacy practices, including how the company responds to DSAR requests.
- Last, but not least, data subjects today are more knowledgeable about the information companies collect, and more educated on how to challenge a DSAR response that appears oddly slim or neatly curated.
Companies are facing a constant challenge to manage personal information across what may be very disparate and complex enterprise systems and repositories. Years of insufficient data management practices make this task a technological challenge. Let’s examine some examples to illustrate several specific gaps that must be addressed to boost effectiveness and efficiency.
Matching Identities Across Tables
The inconsistent management of primary and foreign keys in databases for matching identities across tables is one example of an area that sorely needs improvement. Each table in a database has a key that allows its data to be matched with data in other tables. For instance, a company may have three tables in a database: one with the contact information of its customers; the second with the transaction information of those customers; and the third with the customers’ responses to satisfaction surveys. In the three tables, the customers are identified by their Customer ID number (CID).
The CID is the primary key that links the three tables and allows the company to correctly connect the contact information, transaction, and survey response of the same customer. Management of primary and foreign keys refers to the diligence of tracking how data subjects are identified on the database level so that when a DSAR needs to be fulfilled, the search for the data subject can be done efficiently across those various keys.
The problem many companies are facing is that each database may contain thousands of tables with different keys (foreign) for the same person and no mapping that connects the primary with the foreign keys. Different tables were created by different users of the database, who were only concerned with connecting the few tables they needed to use. The result is a tangle of connections and keys—artifacts left behind by untold numbers of business analysts—that make DSAR requests very hard to satisfy.
Naming Data Elements
The clear naming of data elements in database tables is another common challenge that needs to be corrected so that data subjects can receive a complete view of the data that companies process about them. This is especially relevant when the data is not self-evident to begin with. Machine Learning and Artificial Intelligence, for instance, can figure out that a string of eight digits in a table’s column represents dates, but without clear headers in the table, no technology can figure out whether the date stands for account creation, last transaction, last call for customer service, or any other possible activity. Traditionally, headers were titled without the expectation that others in the company outside of the database administrators and a few users would need to understand them. Privacy regulations require us to rethink this practice and establish new requirements to guide our management of data.
“I Have Orphaned What?”
When we speak of data subjects, we think of those individuals who have transacted with the company in one way or another (employees, applicants, customers, visitors, etc.). One of the dirty secrets of data management is that all companies have many “orphaned identities” in their repositories as well. Orphaned identities are data subjects who cannot be tied to any processing activity or privacy commitment. Orphaned identities might include information that was added by employees who use company resources for personal use (the resumes of nannies, for example), information received in error from partners, tables with no keys, and more. Orphaned identities are still data subjects, and the inappropriate disclosure of this personal information can still trigger breach notification obligations. The ability to find orphaned identities and correct them (eliminate them, most likely) is a data management practice that will help reduce an organization’s risk profile.
Set Standards, Establish Goals, and Reduce Risk
When it comes to unstructured data, such as documents, we need consensus on how to accurately identify an identity in data (e.g., is April Green a name of a person, street, company, or just a noun and adjective in proximity). The choice of technique to address such questions involves a calculation of the statistical confidence that a certain piece of data represents one thing and not the other. Unfortunately, we do not have any standards that will guide our use of statistical confidence when searching for personal information while responding to DSARs. Such standards are important to create consistency and provide the rationale whenever challenged by a data subject or regulator about existing practices.
The correct identification of data subjects across the enterprise will allow organizations to develop a complete and accurate inventory of its data subjects, a goal most companies have yet to achieve. Such an organized view of data subjects is not only the best way to address DSARs but is the first stepping stone to address the other data management tasks companies are facing.
We’ll cover two of the most important priorities for doing this in the next two blogs in this series:







